MNIST 데이터의 손글씨로 적힌 숫자 이미지를 분류하는 다중 분류(Multiclass classification) 문제를 다룰 것이다. 데이터는 여기(https://www.kaggle.com/c/digit-recognizer)에서 얻을 수 있다.
파이토치를 이용하여 인공신경망(Artificial Neural Network)을 구현할 것이다. 구현 과정은 다음과 같다.
1. 데이터 입력 및 확인
2. 데이터 전처리
3. 모델 설정
4. 데이터 학습 및 검증
1. 데이터 입력 및 확인
In:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
▷ 데이터 입력에 pandas, 데이터 전처리에 numpy, 딥러닝 구현에 torch, 시각화에 matplotlib 라이브러리를 이용할 것이다.
In:
df_total = pd.read_csv('../input/train.csv', dtype = np.float32)
▷ pandas의 read_csv()를 이용하여 데이터를 부른다. dtype 인자를 np.float32로 주어 메모리 사용량을 줄일 수 있도록 하자.
In:
print(df_total.columns)
print(df_total.index)
Out:
Index(['label', 'pixel0', 'pixel1', 'pixel2', 'pixel3', 'pixel4', 'pixel5',
'pixel6', 'pixel7', 'pixel8',
...
'pixel774', 'pixel775', 'pixel776', 'pixel777', 'pixel778', 'pixel779',
'pixel780', 'pixel781', 'pixel782', 'pixel783'],
dtype='object', length=785)
RangeIndex(start=0, stop=42000, step=1)
▷ 데이터의 열의 개수는 785개로, 레이블(Label)과 해당 위치의 픽셀(Pixel)에 대한 정보를 담고있다. 각 이미지를 이루는 전체 픽셀의 개수는 784(28×28)개이고, 데이터의 행의 개수는 42,000개이다.
2. 데이터 전처리
In:
arr_feature = df_total.loc[:, df_total.columns != 'label'].values/255
arr_target = df_total.label.values
arr_feature_train, arr_feature_test, arr_target_train, arr_target_test = train_test_split(arr_feature,
arr_target,
test_size = 0.2)
▷ df_total로부터 피처(Feature)와 레이블에 해당하는 부분을 분리하여 arr_feature과 arr_target를 만들었다. arr_feature의 경우, 피처에 255로 나누어 정규화(Normalization)하였다.
▷ train_test_split()을 이용하여 훈련 세트(arr_feature_train, arr_target_train)와 테스트 세트(arr_feature_test, arr_target_test)를 8:2로 나눈다.
In:
ts_feature_train = torch.from_numpy(arr_feature_train)
ts_target_train = torch.from_numpy(arr_target_train).type(torch.LongTensor)
ts_feature_test = torch.from_numpy(arr_feature_test)
ts_target_test = torch.from_numpy(arr_target_test).type(torch.LongTensor)
print(type(ts_feature_train))
print(type(ts_target_train))
print(type(ts_feature_test))
print(type(ts_target_test))
Out:
<class 'torch.Tensor'>
<class 'torch.Tensor'>
<class 'torch.Tensor'>
<class 'torch.Tensor'>
▷ 각 데이터 세트의 데이터 타입을 텐서(Tensor)로 바꾼다.
In:
ds_train = torch.utils.data.TensorDataset(ts_feature_train, ts_target_train)
ds_test = torch.utils.data.TensorDataset(ts_feature_test, ts_target_test)
▷ 각 데이터 세트별 피처와 레이블 텐서를 텐서 데이터 세트(Tensor dataset)로 합친다.
In:
batch_size = 256
ldr_train = torch.utils.data.DataLoader(ds_train,
batch_size = batch_size,
shuffle = True)
ldr_test = torch.utils.data.DataLoader(ds_train,
batch_size = batch_size,
shuffle = True)
batch_size: 훈련 및 테스트 세트의 배치 크기
▷ 훈련 및 테스트 세트의 타입을 데이터로더(Data loader)로 바꾼다. 이 때, batch_size와 shuffle 인자에 값을 주어 데이터 구성을 설정한다.
In:
def get_image(data, idx):
plt.imshow(data[idx].reshape(28, 28))
plt.axis('off')
plt.show()
for i in range(10):
get_image(arr_feature_train, np.where(arr_target_train == i)[0][1])
Out:

▷ 훈련 세트의 각 숫자별 첫 번째 이미지의 결과이다. 각 숫자별 첫 번째의 인덱스를 찾기 위해 np.where()를 이용하였다.
▷ 784개의 픽셀을 28×28의 형태로 만들기 위해 reshape()를 이용하였다.
3. 모델 설정
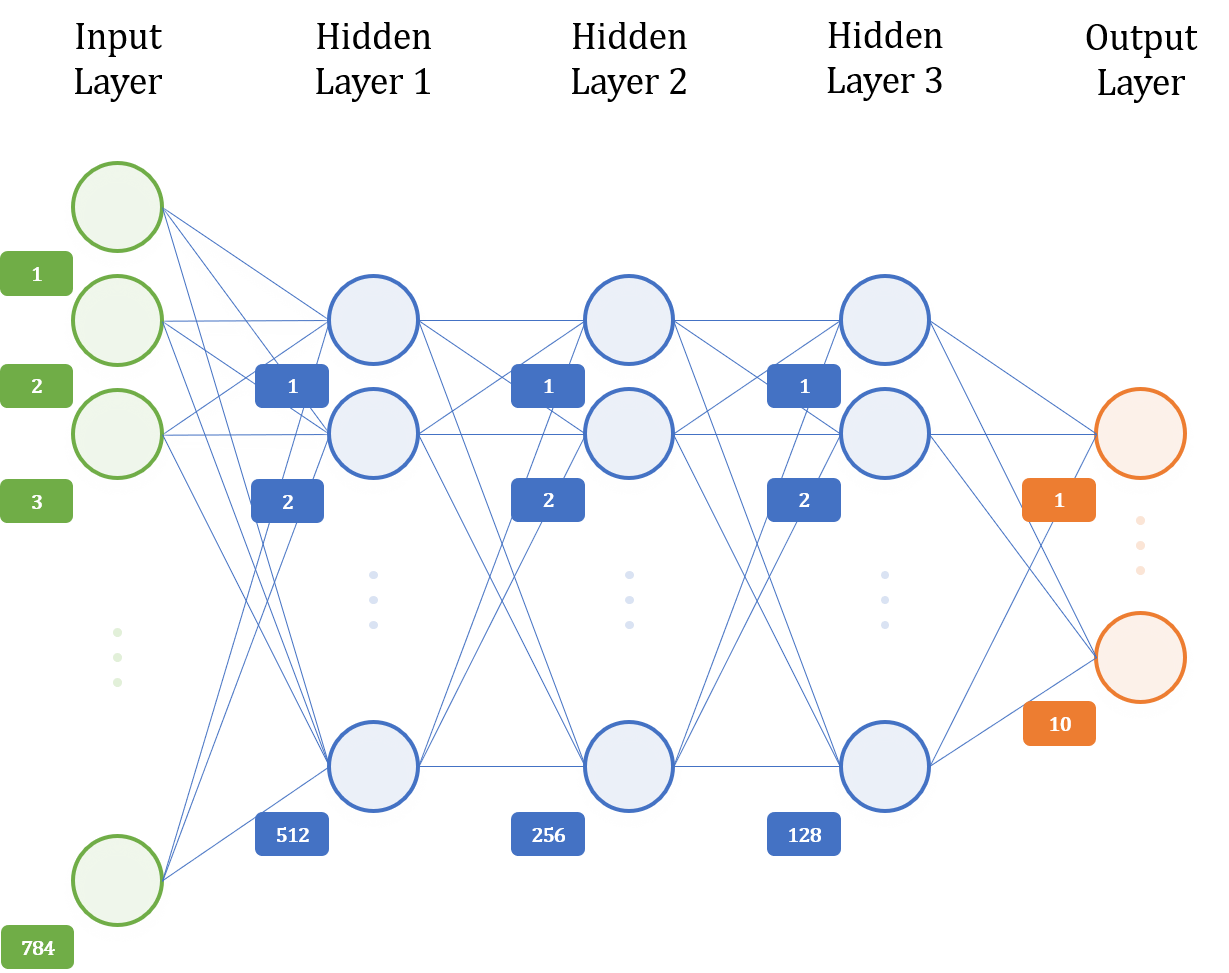
모델의 아키텍쳐(Architecture)는 다음과 같다.
In:
class ANN(nn.Module):
def __init__(self):
super().__init__()
self.fc_1 = nn.Linear(28*28, 512)
self.fc_2 = nn.Linear(512, 256)
self.fc_3 = nn.Linear(256, 128)
self.fc_4 = nn.Linear(128, 64)
self.fc_5 = nn.Linear(64, 10)
self.dropout = nn.Dropout(p = 0.2)
self.log_softmax = F.log_softmax
def forward(self, x):
x = self.dropout(F.relu(self.fc_1(x)))
x = self.dropout(F.relu(self.fc_2(x)))
x = self.dropout(F.relu(self.fc_3(x)))
x = self.dropout(F.relu(self.fc_4(x)))
x = self.log_softmax(self.fc_5(x), dim = 1)
return x
▷ nn.Linear()를 이용하여 모델의 아키텍쳐와 같이 전결합 레이어(Fully-connected layer)를 구성한다.
▷ nn.Dropout()를 이용하여 순전파(Propagation) 과정에 각 노드를 드롭아웃(Dropout)하도록 하였다. 드롭아웃될 확률은 0.2로 설정하였다.
▷ F.log_softmax()를 이용하여 마지막 레이어에서 로그 소프트 맥스(Log softmax)를 계산한다. 이는 교차 엔트로피 오차(Cross entropy loss)를 구하기 위한 작업이다.
▷ F.relu()를 이용하여 활성화 함수(Activation function)로 ReLU 함수를 사용한다. ReLU는 마지막 레이어를 제외한 모든 레이어에 적용된다.
4. 데이터 학습 및 검증
In:
model = ANN()
loss_fun = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr = 0.0001)
▷ loss_fun을 nn.NLLLoss()로 정의함으로써 앞의 로그 소프트 맥스 계산 결과에 적용하여 교차 엔트로피 오차를 구하게 된다.
▷ 모델의 최적화 과정에는 optim.Adam()을 이용하여 진행할 것이다. 학습률(Learning rate)는 0.0001로 설정하였다.
In:
# (1) 학습 파라미터 및 변수 설정
epoch = 25
train_loss, test_loss = [], []
for e in range(epoch):
# (2) 모델 학습
running_loss_train = 0
for image, label in ldr_train:
optimizer.zero_grad()
log_pred = model(image)
loss = loss_fun(log_pred, label)
loss.backward()
optimizer.step()
running_loss_train += loss.item()
# (3) 모델 검증
running_loss_test = 0
accuracy = 0
with torch.no_grad():
model.eval()
for image, label in ldr_test:
log_pred = model(image)
running_loss_test += loss_fun(log_pred, label)
pred = torch.exp(log_pred)
top_prob, top_class = pred.topk(1, dim = 1)
equal = (top_class == label.view(*top_class.shape))
accuracy += torch.mean(equal.type(torch.FloatTensor))
model.train()
train_loss.append(running_loss_train/len(ldr_train))
test_loss.append(running_loss_test/len(ldr_test))
print("Epoch: {}/{}.. ".format(e + 1, epoch),
"Training Loss: {:.3f}.. ".format(train_loss[-1]),
"Test Loss: {:.3f}.. ".format(test_loss[-1]),
"Test Accuracy: {:.3f}".format(accuracy/len(ldr_test)))
(1) 학습 파라미터 및 변수 설정
epoch: 전체 데이터의 학습(순전파와 역전파 과정) 횟수 설정
train_loss, test_loss: 훈련 세트와 테스트 세트의 학습 결과 오차 기록
(2) 모델 학습
running_loss_train: 훈련 세트의 학습 횟수별 오차 기록
▷ optimizer.zero_grad()를 이용하여 옵티마이저(Optimizer)의 경사도를 0으로 만든다. 순전파와 역전파 과정에 따른 업데이트(Update)된 경사도가 누적되기 때문이다. 즉, 배치에 대한 학습이 끝날 때마다 옵티마이저의 경사도를 초기화하기 위한 것이다.
▷ model()을 이용하여 순전파 과정을 수행하여 각 클래스 별 로그 소프트 맥스 값을 구한다. log_pred와 label을 loss_fun()에 인자로 주어 교차 엔트로피 오차를 구한다.
▷ model.eval()을 이용하여 평가모드로 변환한다.
▷ loss.backward()를 이용하여 역전파 과정을 수행하고, optimizer.step()을 이용하여 모델의 파라미터를 업데이트한다.
▷ running_loss_train에 훈련 세트의 모든 배치 loss.item()을 더하여 전체 오차를 구한다.
▷ model.train()을 이용하여 학습모드로 변환한다.
(3) 모델 검증
running_loss_test: 테스트 세트의 학습 횟수별 오차 기록
accuracy: 모델의 예측과 실제 결과를 비교하여 모델의 정확도 기록
▷ torch.no_grad()는 텐서에 저장된 경사도를 지운다. 모델 검증 과정에서 텐서에 저장된 경사도가 필요없기 때문에 with를 이용하여 검증 과정의 모든 텐서에 torch.no_grad()를 적용한다. 이는 메모리 절약 및 연산 속도 증가에 도움이 된다.
▷ model()을 이용하여 학습된 모델을 이용하여 예측하고, log_pred와 label을 loss_fun()에 인자로 주어 교차 엔트로피 오차를 구한다.
▷ running_loss_test에 테스트 세트의 모든 배치 loss.item()을 더하여 전체 오차를 구한다.
▷ torch.exp()를 이용하여 log_pred를 확률로 만들고, torch.topk()를 이용하여 가장 높은 확률을 클래스를 예측 결과로 한다.
▷ torch.view()는 label과 top_class의 형태를 같게 하기 위해 사용되었다. top_class == label을 통해 예측 결과와 실제 레이블이 같으면 1, 아니면 0이란 결과를 얻은 뒤, 평균을 구하여 정확도를 계산하였다.
Out:
Epoch: 1/25.. Training Loss: 1.829.. Test Loss: 0.833.. Test Accuracy: 0.775
Epoch: 2/25.. Training Loss: 0.755.. Test Loss: 0.473.. Test Accuracy: 0.864
Epoch: 3/25.. Training Loss: 0.535.. Test Loss: 0.365.. Test Accuracy: 0.894
Epoch: 4/25.. Training Loss: 0.438.. Test Loss: 0.310.. Test Accuracy: 0.910
Epoch: 5/25.. Training Loss: 0.376.. Test Loss: 0.270.. Test Accuracy: 0.922
Epoch: 6/25.. Training Loss: 0.329.. Test Loss: 0.238.. Test Accuracy: 0.930
Epoch: 7/25.. Training Loss: 0.293.. Test Loss: 0.210.. Test Accuracy: 0.937
Epoch: 8/25.. Training Loss: 0.265.. Test Loss: 0.193.. Test Accuracy: 0.942
Epoch: 9/25.. Training Loss: 0.242.. Test Loss: 0.171.. Test Accuracy: 0.949
Epoch: 10/25.. Training Loss: 0.225.. Test Loss: 0.157.. Test Accuracy: 0.954
Epoch: 11/25.. Training Loss: 0.209.. Test Loss: 0.143.. Test Accuracy: 0.958
Epoch: 12/25.. Training Loss: 0.191.. Test Loss: 0.131.. Test Accuracy: 0.961
Epoch: 13/25.. Training Loss: 0.177.. Test Loss: 0.121.. Test Accuracy: 0.965
Epoch: 14/25.. Training Loss: 0.164.. Test Loss: 0.114.. Test Accuracy: 0.967
Epoch: 15/25.. Training Loss: 0.158.. Test Loss: 0.104.. Test Accuracy: 0.970
Epoch: 16/25.. Training Loss: 0.148.. Test Loss: 0.098.. Test Accuracy: 0.972
Epoch: 17/25.. Training Loss: 0.138.. Test Loss: 0.093.. Test Accuracy: 0.973
Epoch: 18/25.. Training Loss: 0.130.. Test Loss: 0.090.. Test Accuracy: 0.974
Epoch: 19/25.. Training Loss: 0.122.. Test Loss: 0.078.. Test Accuracy: 0.978
Epoch: 20/25.. Training Loss: 0.114.. Test Loss: 0.075.. Test Accuracy: 0.979
Epoch: 21/25.. Training Loss: 0.110.. Test Loss: 0.069.. Test Accuracy: 0.980
Epoch: 22/25.. Training Loss: 0.105.. Test Loss: 0.065.. Test Accuracy: 0.982
Epoch: 23/25.. Training Loss: 0.098.. Test Loss: 0.060.. Test Accuracy: 0.983
Epoch: 24/25.. Training Loss: 0.096.. Test Loss: 0.056.. Test Accuracy: 0.984
Epoch: 25/25.. Training Loss: 0.089.. Test Loss: 0.053.. Test Accuracy: 0.985
In:
plt.plot(train_loss, label = 'Training loss')
plt.plot(test_loss, label = 'Test loss')
plt.xlabel('Epoch')
plt.ylabel('Cross Entropy Loss')
plt.legend(frameon = True)
Out:
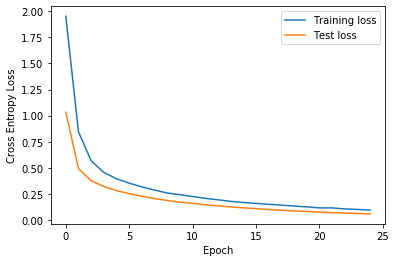
▷ 학습이 진행됨에 따라 훈련 세트와 테스트 세트의 오차가 줄어들고 있는 모습을 확인할 수 있다.
▷ 마지막 에폭(Epoch)에서 테스트 세트의 정확도가 98.5%로 상당히 흡족할 만큼 나왔다. 물론, 정확한 모델의 성능을 측정하기 위해서는 보지 않은(Unseen) 데이터에 대한 검증이 필요할 것이다. 이는 생략하도록 하겠다.
Reference:
"MNIST: Introduction to ComputerVision with PyTorch," Abhinand, https://www.kaggle.com/abhinand05/mnist-introduction-to-computervision-with-pytorch.
'Deep Learning > Model' 카테고리의 다른 글
| LSTM(Long Short-Term Memories model) 구현 (0) | 2020.10.10 |
|---|---|
| 순환 신경망(Recurrent Neural Network) 구현 (0) | 2020.10.01 |
| 합성곱 신경망(Convolutional Neural Network) 구현 (0) | 2020.08.07 |

